![]()
![]()
By James Larson, Copyright 1995. All rights reserved.
As you attempt to do a little strategic planning for your alarm company, the service manager barges into the office with desperate news - the oldest truck in the fleet has finally broken down for good, and he needs to know when it can be replaced.
Then the intercom buzzes - the receptionist reports that one of your biggest accounts is on the line, demanding to speak to you, complaining that her fire system has false alarmed for the fifth time this month, and is expecting you to do something about it. Your service manager says he is sure the equipment is fine, because he checked it out for himself a few days ago, and insists that the problem must be user error.
Next, your lead operator storms in, nostrils flaring, to report that the new operator you insisted she hire isn't working out. Because of his unreliability, she has personally had to work over-time three nights in the last two weeks. She wants to begin looking for a replacement right away.
Another phone call - it's your wife informing you that your youngest daughter fell as a result of a broken piece of play equipment, and that the school nurse insists she be x-rayed to guard against serious injury. Then she calmly reminds you your son needs a ride to basketball practice at six o'clock.
Then, as you pull open your lap drawer to get your bottle of Maalox, you see the note on the desk pad reminding you that the City Council will be discussing a false alarm ordinance that evening. You then remember assuring another big customer you would personally attend that meeting.
It's eleven thirty P.M., and you think you finally made it through another tough day. As you sit on your bed, anticipating some desperately needed sleep, the bedside phone rings. Your lead operator is calling to report that the monitoring computer in the central station has failed, with a message on the screen about "Hard disk failure." You tell her to hang on; you will try to get there as soon as possible with the computer consultant.
Now your stomach is really upset.
It's eleven thirty P.M., and you think you finally made it through another tough day. As you sit on your bed, anticipating some desperately needed sleep, the bedside phone rings. Your lead operator is calling to report that the primary monitoring computer in the central station has failed, with a message on the screen about "Hard disk failure." She goes on to explain that she has followed the appropriate emergency procedures, and that it appears the secondary computer has accepted the signal processing load with no problems. Thanks to the redundancy built into the system, no signals were missed or improperly processed.
You thank her for the information, ask her to make sure the computer consultant is notified first thing the next morning. Then you hang up. Fixing the broken computer will be top priority -- tomorrow.
Computers are seeing increased use in applications where reliability is critical to avoid loss of life and property [1:21]. Examples include fly-by-wire aircraft [2:19], medical radiation machines [3], patient monitoring, manufacturing process-control [4], nuclear power plant monitoring [2:19], telecommunications [5:200], weapon systems, and remote alarm monitoring. Of particular interest to alarm dealers is remote alarm monitoring. If you run a Central Station, how reliable is the monitoring system you use? If you contract with a monitoring service, is the distance between the subscriber and the Central Station an important reliability factor?
Due to increases in solid state circuit integration, and advances in printed circuit mass production, computer reliability has gone from 1.5 seconds to 100,000 hours Mean Time Between Failure (MTBF), with no Preventative Maintenance (PM) required. Indeed, one important reason electronic systems are replacing manual or mechanical ones is because of the reliability gains realized.
Reliability and risk are two sides of the same coin. Risk is a consequence of failure. In computer systems today, the major component of risk isn't hardware, but software. This is because Software Engineering is a relatively new science, struggling to establish norms in education for its practitioners, and standards of quality for its products. These factors are important to Central Station managers because it affects exposure to liability and litigation losses.
Risk is based on the likelihood of failures occurring, the likelihood that the failures will lead to an accident, and the worst possible potential loss associated with such an accident. It is the responsibility of engineers to assess the level of acceptable risk in a proposed system [4]. It is not possible to eliminate all risk from a system design [4:45] [6]. Well designed software and hardware will take active measures to reduce risk through the prudent implementation of interlocks, safety controls, and redundancy, all of which are intended to prevent assumption of dangerous states [4].
A failure is a condition where a system ceases to perform its intended function. Failures are caused by errors [1:21].
Errors are states which are different from what would logically be expected. There are three classes of errors. First, hard errors that leave damage to the system. Second, soft errors which are transient and leave no damage. Third, latent errors which haven't yet been detected. Errors are caused by faults [1:21].
Faults are physical in nature, though a fault does not necessarily produce an error. Faults can be caused by environmental conditions, damage, manufacturing defects, environmental radiation, mistakes in system specifications, design errors, unanticipated inputs, [1:21] and software coding mistakes (bugs).
Digital systems are built from logic gates which are in turn built from switching devices. The first computer system, ENIAC, used thermionic tubes. Tubes work at relatively high temperatures and voltages. Tubes consequently experienced a high failure rate. Then the transistor was invented by Bell Labs in 1947.
Transistors replaced tubes one for one in logic gates. Transistors work at a much lower voltage and temperature. Consequently, systems built with transistors experienced a quantum leap in reliability. However, even the simplest computer logic sub-system required hundreds of transistors, all of which had to be interconnected.
Interconnections between logic elements were the primary source of failures. Integrated Circuits (IC) contain many interconnected transistors formed on a single substrate, wired to perform a common logic or linear function. These substrate interconnections are far more reliable than the interconnections between individual transistors, which resulted in another dramatic increase in system reliability.
IC development has progressed through five distinct levels starting with Small Scale Integration (SSI) to present day Ultra Large Scale Integration (ULSI) technologies. Each level has seen about a 10 to 100 fold increase in the number of gates which could be formed on a single substrate. This caused a phenomenal decrease in size and cost, with a corresponding increase in speed and reliability of computer systems.
Using high density integration technologies, all the complex circuitry of a modern, sophisticated computer can be fabricated with a handful of components. These components can then mounted and interconnected on a Printed Circuit Board (PCB) less than 144 square inches in size.
IC's are extremely reliable. They are becoming even more reliable with improvements in fabrication techniques [7:745] [8:3] [9:686]. IC units tend to have a uniform failure rate at the package level, regardless of the number of components on them [8:3]. This explains why hardware complexity does not seem to affect reliability. Today, the biggest danger to electronic systems is Electrostatic Discharge (ESD) from mishandling [10].
IC circuits are microscopic in size, requiring incredible precision and cleanliness during fabrication. Manufacturing defects affect device yield and reliability, just as with any other product. Manufacturers can use static reconfiguration methods to improve device yield, or dynamic reconfiguration to improve reliability in the field. There are many reconfiguration strategies [11].
One dynamic reconfiguration strategy requires additional spare components to be formed on the substrate, which are used as needed. Another strategy causes performance degradation by doubling the load of components which are still working by forcing them to take over for failed components. Lastly, product classification can be used to sell slightly defective, but still functional, parts. These methods are mixed and matched to achieve balance in design complexity, efficiency, and die size [11].
The Intel 486 is an example of static reconfiguration. The 486 has both a microprocessor and a math co-processor fabricated on a single substrate. Intel was faced with a large number of parts coming off the line which had defects in the math co- processor section. The microprocessor section on these parts were still usable, so Intel strapped out the math co-processor section, added the suffix 'SX', and created the popular 486SX, thus effectively increasing part yield.
Fault-tolerance can also be improved through redundancy at higher system levels. Depending on the system design, fault- detection can cause automatic reconfiguration under software or hardware control, or notify a human operator to affect necessary reconfiguration [7:745]. In the introduction to this article, after the primary monitoring computer failed, the central station lead operator performed the required reconfiguration manually, allowing the secondary computer to continue processing signals.
Most system failures are not caused by part failures, but design problems. Design problems include part tolerance mismatches, electromagnetic interference, timing, and interconnections. IC manufacturers are depending more on Computer Aided Design (CAD) tools, reliability simulation, and mathematical models to improve their designs [9:687] [12:59].
Other factors which contribute to premature system failure include ESD from mishandling, faulty testing, and faulty repair [10]. So, once a particular system is past the infant mortality period of approximately 80 hours, it should work reliably for the next 100,000 hours.
Software has a combination of properties which make it an unique artifact. First, it has mechanical attributes in that each line of program code can be thought of as a separate moving part. This moving part must be interconnected properly with other parts of the system for satisfactory operation. Second, most lines of code within a logical section must execute (or move), serially, in a predetermined sequence, known as program flow. Third, software does not wear out like mechanical parts do. Fourth, defects originate at the time the software is written or changed.
Lines of code can be grouped together and considered a sub- assembly known as a subroutine. A subroutine has the property that it can be used by many different parts of the same system to perform the same basic operation. If there is a defect in the subroutine, all parts of the system which rely on it will be defective, a situation which is easy to identify and correct. Also, extensive use of subroutines make the original coding, and subsequent modifications, easier.
Even simple software systems contain tens of thousands of lines of code, which easily outstrips a human's ability to totally comprehend. Fortunately, any software project can be broken down into smaller units called modules. These modules can be separately written and tested, then integrated into the final system. When properly done, this modularization produces a system which is reliable, flexible, cost effective, and suitable for its intended purpose.
Software systems must change over time to meet the needs of the institutions they serve. Software systems are never finished, they just reach a point where no one is willing to pay for the changes that still need to be made, or they get so out of date they are replaced wholesale. The greatest danger to the reliability of any software system lies within these changes. Often, software maintenance falls on the least experienced person in the data processing department because it is perceived as not glamorous enough by either management or other programmers.
Most all of the present day mass marketed software, such as Microsoft Windows, Novell Word Perfect, Lotus 1-2-3, etc., are designed and maintained by a team of highly skilled, well compensated, programmers and developers. Because these products have a large user base, top quality people are attracted to these teams. Vertical markets, such as alarm monitoring software, may not be as lucrative, therefore cannot be expected to attract the best possible talent.
To illustrate the human cost of this point, consider the Therac-25 radiation overdoses. The Therac-25 is a multi-mode medical accelerator used to treat cancer patients. Three documented deaths resulted from these overdoses from June 1985 to January 1987. The cause of these accidental deaths were ultimately traced to a software "bug" in the computer program which controlled the Therac-25 [3]. Two of the basic software engineering principles violated by the Therac control software include overly complex design, and poor quality assurance [3:40- 41].
The following lessons should be learned from the Therac-25 incidents. One, safety should be built in at the system level. Two, any good engineer is not necessarily a good programmer. Three, what is needed for safety critical applications are programmers with years of experience and training [3:40-41].
Computer programming as a human endeavor is relatively new, requiring pioneers with special aptitude to blaze the trail for those who follow. As a result, programming has a history of being considered an arcane art form. Software Engineering attempts to impose rigorous discipline on this art form.
Today, almost anyone with a computer, a programming language, and ingenuity can claim to be a programmer. When comparing two programs which perform the same basic function, it is difficult to tell which is more efficient, or will be more reliable. What one programmer does in 200 lines of code, another programmer can do in 20 lines as a result in differences in experience and inspiration. Ego and drop dead delivery dates are the bane of sound, reliable, efficient software.
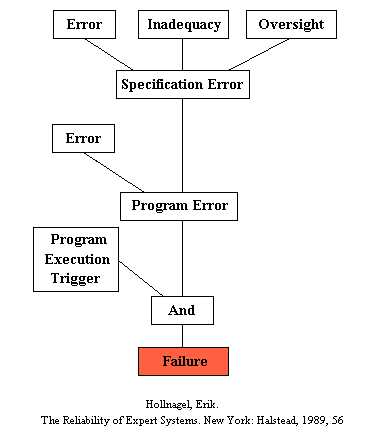
Figure 1 diagrams steps in software failure. These steps will occur in every software system produced. Many factors exasperate the problem. First, years may transpire between the steps illustrated in this diagram. Second, there may be dozens of people involved at each step, with each person having different perceptions, experiences, biases, and competences. Third, deadlines, management pressure, and politics can cause important issues to be given less than adequate attention. Fourth, interpersonal problems and other difficulties in communications can seriously degrade overall team performance. Fifth, the software system, once produced, may be so poorly written and/or documented that adequate review is impossible. Lastly, holding hundreds of variables constant long enough for a system to be designed, written, verified, validated, delivered, and activated requires tremendous intestinal fortitude on the part of all involved. The fact that complex software systems do exist, which actually work well, is a testament to human ingenuity and determination.
Apart from the micro factors afflicting individual software development projects already discussed, there are macro factors which contribute to software failure. First, CS graduates are woefully under-educated in engineering disciplines [13], and often do not have a fundamental mathematical understanding of feedback and stability, yet are called upon to program systems which adjust the flight control surfaces of aircraft. Second, college instructors are often just as deficient [2:19]. Third, many programmers cannot write efficient code [14:8]. Fourth, the demand for skilled personnel to do critical work outstrips supply [13].
Global competition is forcing all industries to improve product quality. Products which are physical in nature, such as computers, vehicles, or a simple normally open door switch, all have well established definitions of quality that all manufacturers understand. Software, which is intellectual in nature, cannot be as readily measured and compared. This makes it difficult to define software quality.
Software Quality Assurance (SQA)
One way to define software quality is the absence of defects, a plethora of features, a fitness for use, with an adherence to accepted standards. Another definition, from Robert Dunn, suggests reliability, usability, maintainability, and salability [5:199]. Even when an acceptable software quality definition is found, reaching it can be very problematic.
While everybody talks software quality, less than 10% of U.S. software organizations take it seriously. A typical U.S. organization will produce three to four defects per 1000 lines of code. Bell Labs was once proud of its three to four defects per 100,000 lines of code until a system wide outage on January 14, 1990, was traced to single bug, and a lack of adequate testing. Another such failure in June of 1991 drove home the point [5:200]. In other industries, a quality factor of 6õ (six standard deviation) gives a company best-in-class status and domination of their respective markets. For software, this works out to three to four defects per million lines of code. Few U.S. organization are anywhere near capable of achieving this level of quality [5:199].
In his book, the Decline & Fall of the American Programmer, Edward Yourdon states;
Approximately 75 percent of U.S. software development organizations has an independent SQA group. However, a recent survey by the American Society of Quality Control indicates that the state of the practice of SQA is abysmal. The survey found the following depressing statistics:
Since most errors in computer systems are transient in nature, they are recoverable. Designs can take advantage of this fact [6]. Dual Computer Redundant Data Applications (DCRDA), designed by the author for use in central station monitoring software, uses two identical computer systems to provide an extremely high level of reliability. Several times over a three month period, one of the computers experienced such a transient error, and locked up; recovery involved cycling the power of the locked up computer.
Another earlier episode left the database on one of the Central Station Monitoring computers totally corrupted; recovery involved copying the working computer's database to the trashed computer, saving tens of hours of manual reconstruction. This is the best possible world.
Does the distance between the Central Station and the subscriber affect reliability? Consider that today's telecommunications network is very complex, extensive, and dependent on sophisticated hardware and software. If a large number of interconnections between components of a computer system degrades reliability, it stands to reason that a large number of communications links between a subscriber and the Central Station will likewise degrade reliability. The more links required, the higher the probability, or risk, of failure.
Peace of mind is the product all alarm companies sell. Perception of reliability is critical to supporting that peace of mind. No matter where a subscriber's alarm system is monitored, the company which services it contributes greatly to that peace of mind. The same can be said for central station monitoring software. Overall reliability of a central station monitoring computer is dependent on hardware and software reliability, but no such system can be made perfect. Ultimately, there must be competent, reliable, dedicated people standing behind any such complex system. If a manager wants peace of mind about the alarm monitoring computer he or she uses, finding the right person to stand behind that hardware and software is critical. When any system fails, it takes a highly skilled, intelligent, competent person with integrity to go in and put it right. With that kind of support system in place, even a central station manager can enjoy peace of mind.
References | |
| [1] | Nelson, Victor P. "Fault-Tolerant Computing: Fundamental Concepts." Computer, 23 (July 1990), 21-25. |
| [2] | Parnas, David. "Education for Computing Professionals." Computer, 23 (January 1990), 17-22. |
| [3] | Leveson, Nancy G. and Clark S. Turner. An Investigation of the Therac-25 Accidents. University of Washington at Seattle Washington, 1992. |
| [4] | Leveson, Nancy G. "Software safety in imbedded computer systems." Communications of the ACM, 34 (February 1991), 34-46. |
| [5] | Yourdon, Edward. Decline & Fall of the American Programmer Englewood Cliffs, New Jersey: Yourdon Press PTR Prentice Hall, 1992. |
| [6] | Singh, Adit D. and Singaravel Murugesan. "Fault-Tolerant Systems." Computer, 23 (July 1990), 15-17. |
| [7] | Peercy, Michael, Prithviraj Banerjee. "Fault Tolerant VLSI Systems." Proceedings of the IEEE, 81 (May 1993), 745-758. |
| [8] | Camp, R.C., T.A. Smay, and C.J. Triska. Microprocessor Systems Engineering. Beaverton, Oregon: Matrix Publishers, Inc., 1979. |
| [9] | Hu, Chenning. "Future CMOS Scaling and Reliability." Proceedings of the IEEE, 81 (May 1993), 682-689. |
| [10] | Interview, Topic: Computer System Reliability by Technology. With Earl Sharp, Communications Electronics Certificate from Montgomery County Joint Vocational School, 16 years as an electronic service technician and teacher; and with Roger Larson, Senior Staff Engineer, SRL, B.S. Engineering Physics, 38 years experience, at Mr. Larson's residence, October 24, 1993. |
| [11] | Chean, Mengly, and Jose A. B. Fortes. "A Taxonomy of Reconfiguration Techniques for Fault-Tolerant Processor Arrays." Computer, 23 (January 1990), 55-67. |
| [12] | O'Connor, Patrick D. T. "Reliability Prediction: Help or Hoax?" Solid State Technology, 33 (August 1990), 59-61. |
| [13] | Buckley, Fletcher J. "A standard environment for software production." Computer, 23 (January 1990), 75-77. |
| [14] | McGonnigal, Grace, Sarah Hancock, Mike Dunlavey, Bruce Walker, Peter Gottlieb, and David L. Parnas. "Letters to the Editor: Parnas' position praised, pilloried." Computer, 23 (April 1990), 8. |
| Visitor # |
|---|